Introduction to the Bass Diffusion Model#
What is the Bass Model?#
The Bass diffusion model, developed by Frank Bass in 1969, is a mathematical model that describes how new products get adopted in a population over time. It’s widely used in marketing to forecast sales of new products, especially when historical data is limited or non-existent.
The model captures the entire lifecycle of product adoption, from introduction to saturation, making it a powerful tool for product planning and marketing strategy development.
The Motivation Behind the Bass Model#
Before the Bass model, companies struggled to predict the adoption patterns of new products. Traditional forecasting methods often failed because they couldn’t account for the social dynamics that drive product adoption. Frank Bass recognized that product adoption follows a distinct pattern:
Initial slow growth: When a product first launches, adoption starts slowly
Rapid acceleration: As more people adopt, word-of-mouth spreads and adoption accelerates
Eventual saturation: Eventually, the market becomes saturated and adoption slows down
The Bass model provides a mathematical framework to capture these patterns, enabling businesses to make more informed decisions about production planning, inventory management, and marketing resource allocation.
Mathematical Formulation#
The Bass model is based on a differential equation that describes the rate of adoption:
Where:
\(F(t)\) is the installed base fraction (cumulative proportion of adopters)
\(f(t)\) is the rate of change of the installed base fraction (\(f(t) = F'(t)\))
\(p\) is the coefficient of innovation or external influence
\(q\) is the coefficient of imitation or internal influence
The solution to this equation gives the adoption curve:
The adoption rate at time \(t\) is given by:
Alternatively, this can be written as:
Key Components of the Bass Model Implementation#
The Bass model implementation in PyMC Marketing consists of several key components:
Adopters - The number of new adoptions at time \(t\):
Innovators - Adoptions driven by external influence (advertising, etc.):
Imitators - Adoptions driven by internal influence (word-of-mouth):
Peak Adoption Time - When the adoption rate reaches its maximum:
The total number of adopters over time is the sum of innovators and imitators, which equals \(\text{adopters}(t)\). All of these components are directly implemented in the PyMC model, allowing us to analyze each aspect of the diffusion process separately.
Understanding the Relationship Between Components#
A key insight of the Bass model is how it decomposes adoption into two sources:
At each time point:
Innovators (\(m \cdot p \cdot (1 - F(t))\)) represents new adoptions coming from people who are influenced by external factors like advertising
Imitators (\(m \cdot q \cdot F(t) \cdot (1 - F(t))\)) represents new adoptions coming from people who are influenced by previous adopters
As time progresses:
Initially, innovators dominate the adoption process when few people have adopted (\(F(t)\) is small)
Later, imitators become the primary source of new adoptions as the word-of-mouth effect grows
Eventually, both decrease as the market approaches saturation (\(F(t)\) approaches 1)
The cumulative adoption at any time point is:
This means that as \(t \to \infty\), the cumulative adoption approaches the total market potential \(m\):
Therefore, the Bass model provides a complete accounting of the market:
At each time point, new adopters are either innovators or imitators
Over the entire product lifecycle, all potential adopters (m) eventually adopt the product
The model tracks both the adoption rate (new adopters per time period) and the cumulative adoption (total adopters to date)
This structure enables marketers to understand not just how many people will adopt over time, but also the driving forces behind adoption at different stages of the product lifecycle.
Understanding the Key Parameters#
The model has three main parameters:
Market potential (m): Total number of eventual adopters (the ultimate market size)
Innovation coefficient (p): Measures external influence like advertising and media - typically \(0.01-0.03\)
Imitation coefficient (q): Measures internal influence like word-of-mouth - typically \(0.3-0.5\)
Parameter Interpretation#
A higher p value indicates stronger external influence (advertising, marketing)
A higher q value indicates stronger internal influence (word-of-mouth, social interactions)
The ratio q/p indicates the relative strength of internal vs. external influences
The peak of adoption occurs at time
Innovators vs. Imitators#
The Bass model distinguishes between two types of adopters:
Innovators: People who adopt independently of others’ decisions, influenced mainly by mass media and external communications
Mathematically represented as: \(\text{innovators}(t) = m \cdot p \cdot (1 - F(p, q, t))\)
Imitators: People who adopt because of social influence and word-of-mouth from previous adopters
Mathematically represented as: \(\text{imitators}(t) = m \cdot q \cdot F(p, q, t) \cdot (1 - F(p, q, t))\)
Real-World Applications#
The Bass model has been successfully applied to forecast the adoption of various products and technologies:
Consumer durables: TVs, refrigerators, washing machines
Technology products: Smartphones, computers, software
Pharmaceutical products: New drugs and treatments
Entertainment products: Movies, games, streaming services
Services and subscriptions: Banking services, subscription plans
Business Value: Why the Bass Model Matters to Executives and Marketers#
From a business perspective, the Bass diffusion model provides substantial competitive advantages and ROI benefits:
1. Resource Optimization and Cash Flow Management#
Production Planning: Avoid costly overproduction or stockouts by accurately forecasting demand curves
Marketing Budget Allocation: Optimize spending across the product lifecycle, investing more during key inflection points
Supply Chain Efficiency: Coordinate with suppliers and distributors based on predicted adoption rates
Cash Flow Optimization: Better predict revenue streams, improving financial planning and investor relations
2. Strategic Decision Making#
Launch Timing: Determine the optimal time to enter a market based on diffusion patterns
Pricing Strategy: Implement dynamic pricing strategies aligned with the adoption curve
Competitive Analysis: Compare your product’s adoption parameters with competitors to identify strengths and weaknesses
Product Portfolio Management: Make informed decisions about when to phase out older products and introduce new ones
3. Risk Mitigation#
Scenario Planning: Test different market assumptions and external factors through parameter variations
Early Warning System: Identify deviations from expected adoption curves early, enabling faster intervention
Investment Justification: Provide data-driven forecasts to justify R&D and marketing investments to stakeholders
4. Performance Measurement#
Marketing Effectiveness: Measure the impact of marketing campaigns on the innovation coefficient (p)
Word-of-Mouth Strength: Quantify the power of your brand’s social influence through the imitation coefficient (q)
Total Market Potential: Validate or adjust your total addressable market estimates (m)
In today’s data-driven business environment, companies that effectively utilize models like Bass diffusion gain a significant competitive edge through more precise forecasting, better resource allocation, and strategic market timing.
Bayesian Extensions#
In this notebook, we show how to generate simulated data from the Bass model and fit a Bayesian model to it. The Bayesian formulation offers several advantages:
Uncertainty quantification through prior distributions on parameters
Hierarchical modeling for multiple products or markets
Incorporation of expert knowledge through informative priors
Full probability distributions for future adoption forecasts
What we’ll do in this notebook#
In this notebook, we’ll:
Set up parameters for a Bass model simulation
Generate simulated adoption data for multiple products
Fit the Bass model to our simulated data using PyMC
Visualize the adoption curves
Prepare Notebook#
from typing import Any
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import numpy.typing as npt
import pandas as pd
import pymc as pm
import xarray as xr
from pymc_marketing.bass.model import create_bass_model
from pymc_marketing.plot import plot_curve
from pymc_marketing.prior import Prior, Scaled
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
seed: int = sum(map(ord, "bass"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
Setting Up Simulation Parameters#
First, we’ll set up the parameters for our simulation. This includes:
The time period for our simulation (in weeks)
The number of products to simulate
Start dates for the simulation period
def setup_simulation_parameters(
n_weeks: int = 52,
n_products: int = 9,
start_date: str = "2023-01-01",
cutoff_start_date: str = "2023-12-01",
) -> tuple[
npt.NDArray[np.int_],
pd.DatetimeIndex,
pd.DatetimeIndex,
list[str],
pd.Series,
dict[str, Any],
]:
"""Set up initial parameters for the Bass diffusion model simulation.
Parameters
----------
n_weeks : int
Number of weeks to simulate
n_products : int
Number of products to include in the simulation
start_date : str
Starting date for the simulation period
cutoff_start_date : str
Latest possible start date for products
Returns
-------
T : numpy.ndarray
Time array (weeks)
possible_dates : pandas.DatetimeIndex
All dates in the simulation period
possible_start_dates : pandas.DatetimeIndex
Possible start dates for products
products : list
List of product names
product_start : pandas.Series
Start date for each product
coords : dict
Coordinates for PyMC model
"""
# Set a seed for reproducibility
seed = sum(map(ord, "bass"))
rng = np.random.default_rng(seed)
# Create time array and date range
T = np.arange(n_weeks)
possible_dates = pd.date_range(start_date, freq="W-MON", periods=n_weeks)
cutoff_start_date = pd.to_datetime(cutoff_start_date)
cutoff_start_date = cutoff_start_date + pd.DateOffset(weeks=1)
possible_start_dates = possible_dates[possible_dates < cutoff_start_date]
# Generate product names and random start dates
products = [f"P{i}" for i in range(n_products)]
product_start = pd.Series(
rng.choice(possible_start_dates, size=len(products)),
index=pd.Index(products, name="product"),
)
coords = {"T": T, "product": products}
return T, possible_dates, possible_start_dates, products, product_start, coords
Creating Prior Distributions#
For our Bayesian Bass model, we need to specify prior distributions for the key parameters:
m (market potential): How many units can potentially be sold in total
p (innovation coefficient): Rate of adoption from external influences
q (imitation coefficient): Rate of adoption from internal/social influences
likelihood: The probability distribution that models the observed adoption data
For the market potential m we use a scaling trick to specify a scale-free prior and then add a global factor:
def create_bass_priors(factor: float) -> dict[str, Prior | Scaled]:
"""Define prior distributions for the Bass model parameters.
Returns
-------
dict
Dictionary of prior distributions for m, p, q, and likelihood
Notes
-----
- m: Market potential (scaled Gamma distribution)
- p: Innovation coefficient (Beta distribution)
- q: Imitation coefficient (Beta distribution)
- likelihood: Observation model (Negative Binomial)
"""
return {
# We use a scaled Gamma distribution for the market potential.
"m": Scaled(Prior("Gamma", mu=1, sigma=0.001, dims="product"), factor=factor),
"p": Prior("Beta", mu=0.03, sigma=0.01 / 2, dims="product"),
"q": Prior("Beta", mu=0.38, sigma=0.1 / 2, dims="product"),
"likelihood": Prior("NegativeBinomial", n=1.5, dims="product"),
}
Let’s generate and visualize the priors.
FACTOR = 50_000
priors = create_bass_priors(factor=FACTOR)
fig, ax = plt.subplots(nrows=2, ncols=1, figsize=(15, 12))
priors["p"].preliz.plot_pdf(ax=ax[0])
ax[0].set(title="Innovation Coefficient (p)")
priors["q"].preliz.plot_pdf(ax=ax[1])
ax[1].set(title="Imitation Coefficient (q)")
fig.suptitle(
"Prior Distributions for Bass Model Parameters",
fontsize=18,
fontweight="bold",
y=0.95,
);
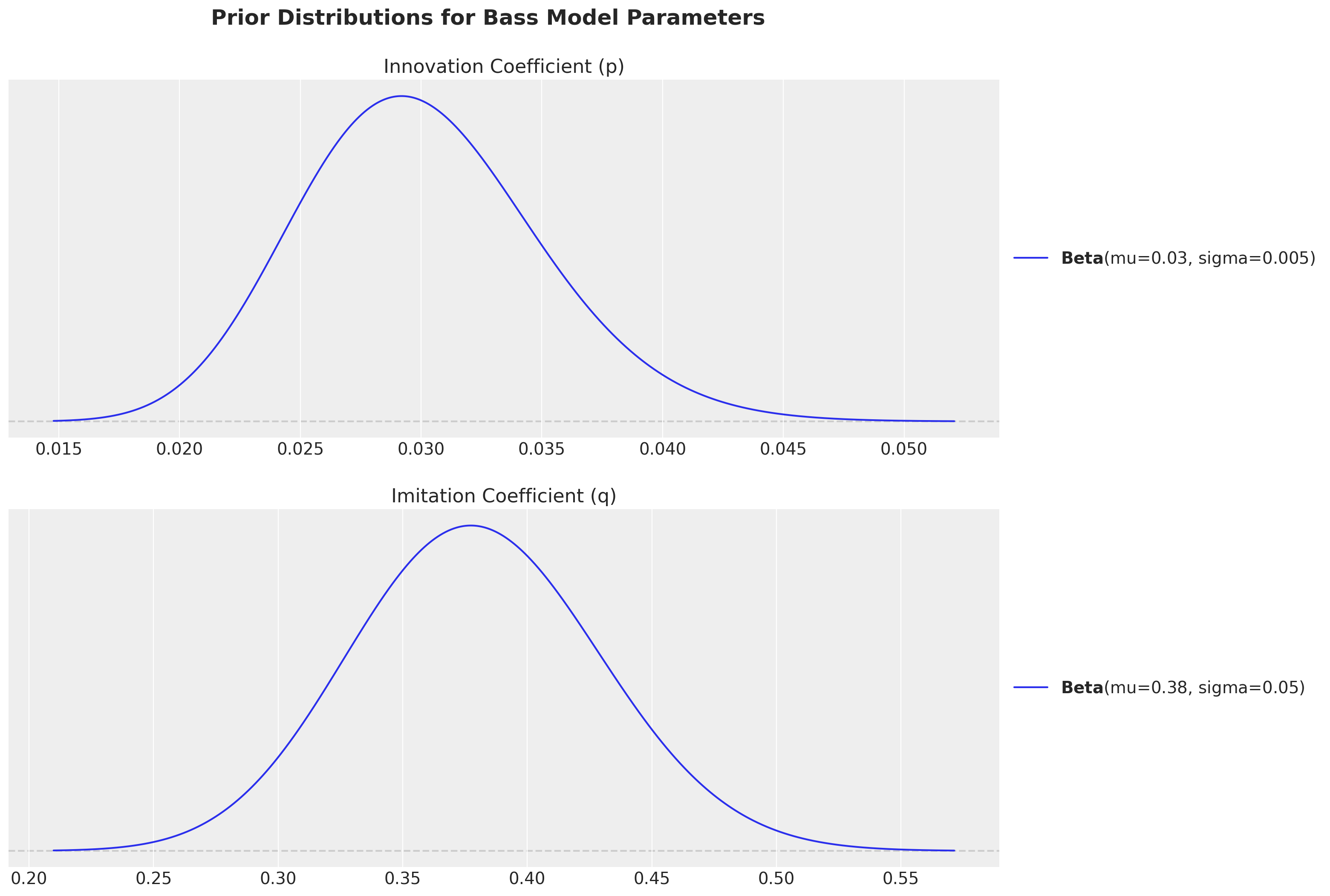
Observe we have chosen the priors within the usual ranges of empirical studies:
Innovation coefficient (p): Measures external influence like advertising and media - typically \(0.01-0.03\)
Imitation coefficient (q): Measures internal influence like word-of-mouth - typically \(0.3-0.5\)
Generate Synthetic Data#
With the generative Bass model, we can generate a synthetic dataset by sampling from the prior and choosing one particular sample to use as observed data. For this purpose we define two auxiliary functions.
def sample_prior_bass_data(model: pm.Model) -> xr.DataArray:
"""Generate a sample from the prior predictive distribution of the Bass model.
Parameters
----------
model : pymc.Model
The PyMC model to sample from
Returns
-------
xarray.DataArray
Simulated adoption data
"""
with model:
idata = pm.sample_prior_predictive(random_seed=rng)
return idata["prior"]["y"].sel(chain=0, draw=0)
def transform_to_actual_dates(bass_data, product_start, possible_dates) -> pd.DataFrame:
"""Transform simulation data from time index to calendar dates.
Parameters
----------
bass_data : xarray.DataArray
Simulated bass model data
product_start : pandas.Series
Start date for each product
possible_dates : pandas.DatetimeIndex
All dates in the simulation period
Returns
-------
pandas.DataFrame
Adoption data with actual calendar dates
"""
bass_data = bass_data.to_dataset()
bass_data["product_start"] = product_start.to_xarray()
df_bass_data = (
bass_data.to_dataframe().drop(columns=["chain", "draw"]).reset_index()
)
df_bass_data["actual_date"] = df_bass_data["product_start"] + pd.to_timedelta(
7 * df_bass_data["T"], unit="days"
)
return (
df_bass_data.set_index(["actual_date", "product"])
.y.unstack(fill_value=0)
.reindex(possible_dates, fill_value=0)
)
Now we can generate the observed data:
# Setup simulation parameters
T, possible_dates, _, products, product_start, coords = setup_simulation_parameters()
# Create and configure the Bass model
generative_model = create_bass_model(t=T, coords=coords, observed=None, priors=priors)
# Sample and select one "observed" dataset.
bass_data = sample_prior_bass_data(generative_model)
actual_data = transform_to_actual_dates(bass_data, product_start, possible_dates)
Sampling: [m_unscaled, p, q, y]
The actual_data data frame has the typical format of a real dataset.
actual_data
| product | P0 | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 |
|---|---|---|---|---|---|---|---|---|---|
| 2023-01-02 | 0 | 0 | 36 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2023-01-09 | 0 | 0 | 194 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2023-01-16 | 0 | 0 | 324 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2023-01-23 | 0 | 0 | 79 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2023-01-30 | 0 | 25 | 236 | 0 | 0 | 11 | 0 | 0 | 0 |
| 2023-02-06 | 0 | 125 | 578 | 0 | 0 | 93 | 0 | 0 | 0 |
| 2023-02-13 | 0 | 406 | 502 | 0 | 0 | 59 | 0 | 0 | 0 |
| 2023-02-20 | 0 | 113 | 24 | 0 | 0 | 169 | 0 | 0 | 0 |
| 2023-02-27 | 0 | 654 | 256 | 87 | 0 | 30 | 0 | 0 | 0 |
| 2023-03-06 | 0 | 417 | 160 | 6 | 0 | 10 | 0 | 0 | 0 |
| 2023-03-13 | 99 | 228 | 190 | 52 | 0 | 125 | 0 | 0 | 0 |
| 2023-03-20 | 55 | 358 | 81 | 1443 | 0 | 1088 | 0 | 0 | 0 |
| 2023-03-27 | 208 | 924 | 57 | 239 | 0 | 171 | 0 | 0 | 0 |
| 2023-04-03 | 188 | 191 | 46 | 366 | 0 | 68 | 0 | 0 | 0 |
| 2023-04-10 | 51 | 478 | 176 | 244 | 0 | 216 | 0 | 0 | 0 |
| 2023-04-17 | 725 | 40 | 36 | 118 | 0 | 50 | 0 | 0 | 0 |
| 2023-04-24 | 284 | 18 | 34 | 506 | 0 | 65 | 0 | 0 | 0 |
| 2023-05-01 | 237 | 151 | 37 | 68 | 0 | 63 | 0 | 0 | 0 |
| 2023-05-08 | 400 | 66 | 54 | 43 | 0 | 51 | 0 | 0 | 0 |
| 2023-05-15 | 64 | 20 | 19 | 52 | 0 | 58 | 0 | 0 | 0 |
| 2023-05-22 | 72 | 7 | 2 | 24 | 0 | 84 | 0 | 0 | 0 |
| 2023-05-29 | 202 | 8 | 5 | 36 | 0 | 14 | 0 | 0 | 0 |
| 2023-06-05 | 362 | 16 | 4 | 3 | 0 | 23 | 0 | 0 | 0 |
| 2023-06-12 | 98 | 11 | 0 | 18 | 0 | 8 | 0 | 0 | 0 |
| 2023-06-19 | 28 | 4 | 0 | 15 | 0 | 5 | 0 | 0 | 0 |
| 2023-06-26 | 22 | 4 | 0 | 8 | 0 | 20 | 0 | 0 | 0 |
| 2023-07-03 | 31 | 1 | 0 | 2 | 0 | 4 | 0 | 0 | 0 |
| 2023-07-10 | 4 | 1 | 0 | 3 | 0 | 6 | 0 | 0 | 0 |
| 2023-07-17 | 19 | 1 | 0 | 0 | 0 | 3 | 0 | 0 | 0 |
| 2023-07-24 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 66 |
| 2023-07-31 | 7 | 1 | 0 | 2 | 0 | 0 | 0 | 0 | 72 |
| 2023-08-07 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 82 |
| 2023-08-14 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 14 |
| 2023-08-21 | 3 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 236 |
| 2023-08-28 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 337 |
| 2023-09-04 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 243 | 401 |
| 2023-09-11 | 2 | 0 | 0 | 0 | 0 | 0 | 111 | 337 | 196 |
| 2023-09-18 | 0 | 1 | 0 | 0 | 0 | 0 | 184 | 234 | 110 |
| 2023-09-25 | 0 | 0 | 0 | 0 | 0 | 0 | 135 | 1011 | 336 |
| 2023-10-02 | 0 | 0 | 0 | 0 | 0 | 0 | 92 | 362 | 255 |
| 2023-10-09 | 0 | 0 | 0 | 0 | 0 | 0 | 206 | 246 | 89 |
| 2023-10-16 | 0 | 0 | 0 | 0 | 0 | 0 | 1108 | 246 | 263 |
| 2023-10-23 | 0 | 0 | 0 | 0 | 0 | 0 | 96 | 479 | 20 |
| 2023-10-30 | 0 | 0 | 0 | 0 | 91 | 0 | 612 | 361 | 429 |
| 2023-11-06 | 0 | 0 | 0 | 0 | 50 | 0 | 70 | 63 | 17 |
| 2023-11-13 | 0 | 0 | 0 | 0 | 196 | 0 | 59 | 157 | 12 |
| 2023-11-20 | 0 | 0 | 0 | 0 | 95 | 0 | 454 | 207 | 47 |
| 2023-11-27 | 0 | 0 | 0 | 0 | 289 | 0 | 134 | 253 | 36 |
| 2023-12-04 | 0 | 0 | 0 | 0 | 710 | 0 | 101 | 26 | 18 |
| 2023-12-11 | 0 | 0 | 0 | 0 | 28 | 0 | 108 | 89 | 18 |
| 2023-12-18 | 0 | 0 | 0 | 0 | 108 | 0 | 68 | 100 | 15 |
| 2023-12-25 | 0 | 0 | 0 | 0 | 82 | 0 | 74 | 6 | 4 |
On the other hand, the bass_data has the same data as arrays indexed by time (relative) and product.
Let’s visualize both.
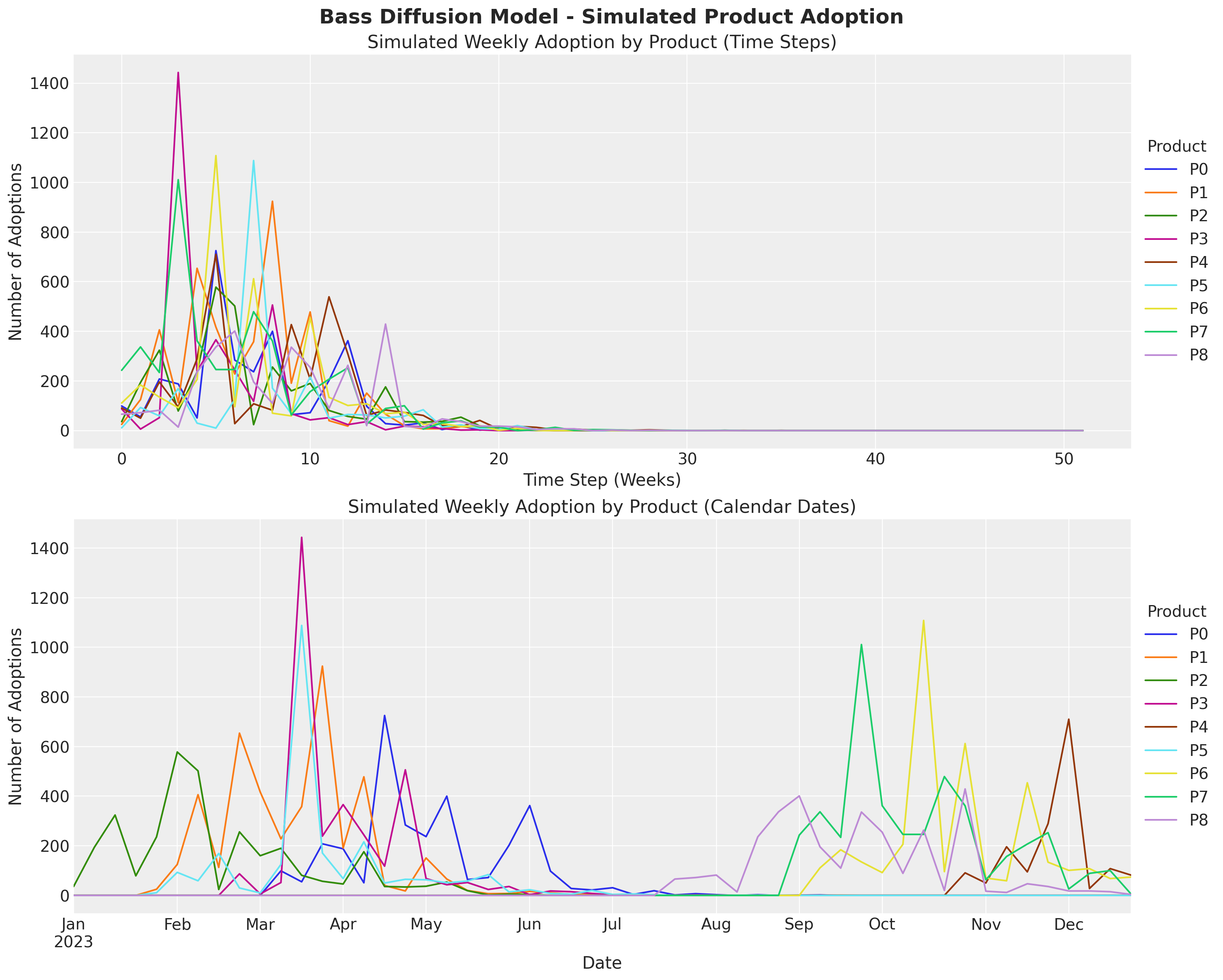
fig, ax = plt.subplots(
nrows=2, ncols=1, figsize=(15, 12), sharex=False, sharey=True, layout="constrained"
)
# Plot raw simulated data (by time step)
bass_data.to_series().unstack().plot(ax=ax[0])
ax[0].legend(
title="Product", title_fontsize=14, loc="center left", bbox_to_anchor=(1, 0.5)
)
ax[0].set(
title="Simulated Weekly Adoption by Product (Time Steps)",
xlabel="Time Step (Weeks)",
ylabel="Number of Adoptions",
)
# Plot data with actual calendar dates
actual_data.plot(ax=ax[1])
ax[1].legend(
title="Product", title_fontsize=14, loc="center left", bbox_to_anchor=(1, 0.5)
)
ax[1].set(
title="Simulated Weekly Adoption by Product (Calendar Dates)",
xlabel="Date",
ylabel="Number of Adoptions",
)
fig.suptitle(
"Bass Diffusion Model - Simulated Product Adoption", fontsize=18, fontweight="bold"
);
Fit the Model#
We are now ready to fit the model and generate the posterior predictive distributions.
# We condition the model on observed data.
with pm.observe(generative_model, {"y": bass_data.values}) as model:
idata = pm.sample(
tune=1_500,
draws=2_000,
chains=4,
nuts_sampler="nutpie",
compile_kwargs={"mode": "NUMBA"},
random_seed=rng,
)
idata.extend(
pm.sample_posterior_predictive(
idata, model=model, extend_inferencedata=True, random_seed=rng
)
)
Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for now
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 3500 | 0 | 0.69 | 7 | |
| 3500 | 0 | 0.69 | 7 | |
| 3500 | 0 | 0.68 | 7 | |
| 3500 | 0 | 0.69 | 7 |
Sampling: [y]
We do not have any divergences. Let’s look at the summary of the parameters.
az.summary(data=idata, var_names=["p", "q", "m"])
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| p[P0] | 0.028 | 0.004 | 0.022 | 0.035 | 0.000 | 0.000 | 19625.0 | 5784.0 | 1.0 |
| p[P1] | 0.031 | 0.004 | 0.024 | 0.038 | 0.000 | 0.000 | 22744.0 | 6087.0 | 1.0 |
| p[P2] | 0.029 | 0.004 | 0.022 | 0.035 | 0.000 | 0.000 | 21865.0 | 6482.0 | 1.0 |
| p[P3] | 0.032 | 0.004 | 0.025 | 0.039 | 0.000 | 0.000 | 18618.0 | 5779.0 | 1.0 |
| p[P4] | 0.027 | 0.003 | 0.021 | 0.033 | 0.000 | 0.000 | 19278.0 | 6548.0 | 1.0 |
| p[P5] | 0.024 | 0.003 | 0.017 | 0.030 | 0.000 | 0.000 | 19607.0 | 5645.0 | 1.0 |
| p[P6] | 0.030 | 0.004 | 0.023 | 0.037 | 0.000 | 0.000 | 19315.0 | 6526.0 | 1.0 |
| p[P7] | 0.034 | 0.004 | 0.027 | 0.041 | 0.000 | 0.000 | 18583.0 | 6109.0 | 1.0 |
| p[P8] | 0.025 | 0.003 | 0.019 | 0.032 | 0.000 | 0.000 | 21261.0 | 6134.0 | 1.0 |
| q[P0] | 0.387 | 0.014 | 0.360 | 0.413 | 0.000 | 0.000 | 19869.0 | 5773.0 | 1.0 |
| q[P1] | 0.387 | 0.015 | 0.360 | 0.414 | 0.000 | 0.000 | 20627.0 | 5563.0 | 1.0 |
| q[P2] | 0.372 | 0.013 | 0.346 | 0.396 | 0.000 | 0.000 | 18371.0 | 6149.0 | 1.0 |
| q[P3] | 0.455 | 0.019 | 0.417 | 0.488 | 0.000 | 0.000 | 21950.0 | 5866.0 | 1.0 |
| q[P4] | 0.319 | 0.012 | 0.297 | 0.340 | 0.000 | 0.000 | 21452.0 | 5974.0 | 1.0 |
| q[P5] | 0.353 | 0.013 | 0.329 | 0.377 | 0.000 | 0.000 | 25087.0 | 6500.0 | 1.0 |
| q[P6] | 0.375 | 0.014 | 0.348 | 0.400 | 0.000 | 0.000 | 22732.0 | 6189.0 | 1.0 |
| q[P7] | 0.330 | 0.012 | 0.308 | 0.353 | 0.000 | 0.000 | 19555.0 | 6141.0 | 1.0 |
| q[P8] | 0.336 | 0.012 | 0.315 | 0.358 | 0.000 | 0.000 | 20631.0 | 5849.0 | 1.0 |
| m[P0] | 50000.162 | 49.220 | 49911.114 | 50092.819 | 0.336 | 0.622 | 21522.0 | 6217.0 | 1.0 |
| m[P1] | 49999.776 | 50.442 | 49911.002 | 50098.496 | 0.362 | 0.702 | 19469.0 | 5585.0 | 1.0 |
| m[P2] | 50000.023 | 49.510 | 49908.858 | 50094.166 | 0.321 | 0.639 | 23623.0 | 6301.0 | 1.0 |
| m[P3] | 50000.153 | 49.263 | 49904.000 | 50089.367 | 0.336 | 0.623 | 21453.0 | 5811.0 | 1.0 |
| m[P4] | 50000.109 | 48.947 | 49912.149 | 50097.660 | 0.340 | 0.687 | 20831.0 | 5712.0 | 1.0 |
| m[P5] | 49999.750 | 48.974 | 49902.908 | 50086.002 | 0.338 | 0.610 | 21047.0 | 6166.0 | 1.0 |
| m[P6] | 50000.284 | 49.741 | 49909.945 | 50094.064 | 0.333 | 0.675 | 22285.0 | 5602.0 | 1.0 |
| m[P7] | 49999.871 | 49.816 | 49906.288 | 50094.007 | 0.331 | 0.643 | 22643.0 | 6009.0 | 1.0 |
| m[P8] | 50000.335 | 49.921 | 49902.734 | 50091.605 | 0.344 | 0.664 | 21006.0 | 5100.0 | 1.0 |
_ = az.plot_trace(
data=idata,
var_names=["p", "q", "m"],
compact=True,
backend_kwargs={"figsize": (12, 7), "layout": "constrained"},
)
plt.gcf().suptitle("Model Trace", fontsize=16);
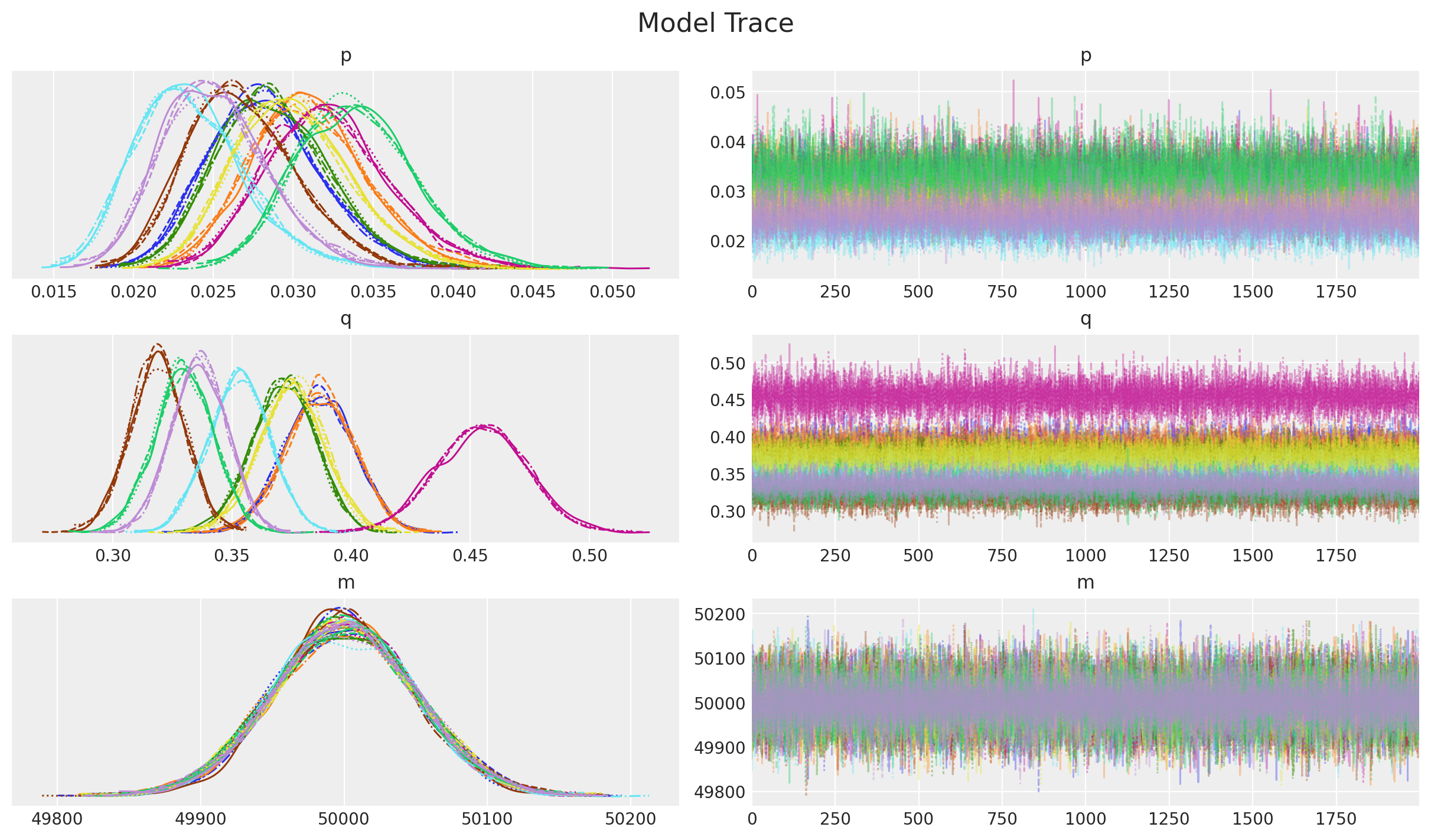
Overall, the diagnostics and trace look good.
Next, we look into the posterior distributions of the parameters.
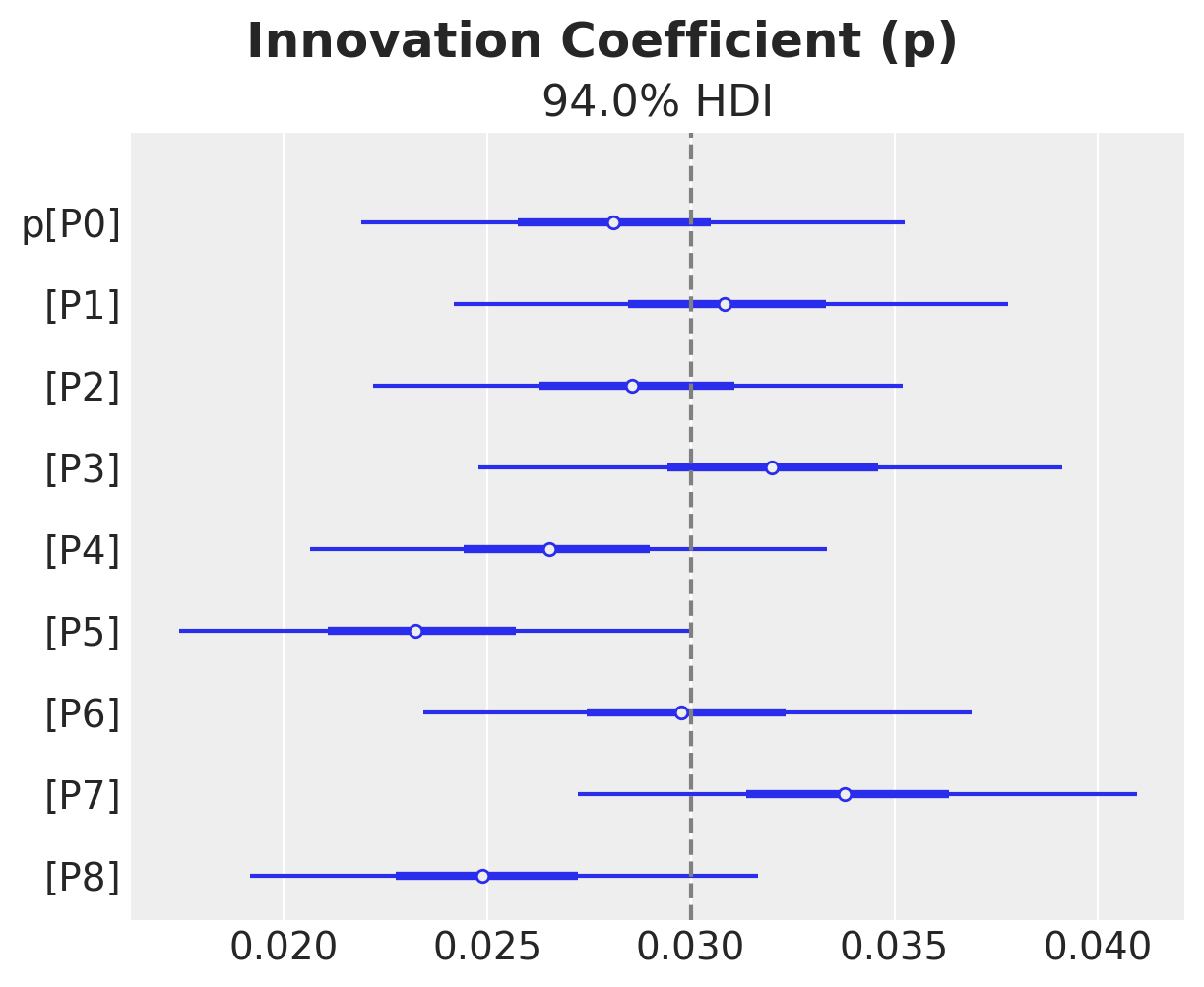
ax, *_ = az.plot_forest(idata["posterior"]["p"], combined=True)
ax.axvline(x=priors["p"].parameters["mu"], color="gray", linestyle="--")
ax.get_figure().suptitle("Innovation Coefficient (p)", fontsize=18, fontweight="bold")
Text(0.5, 0.98, 'Innovation Coefficient (p)')
ax, *_ = az.plot_forest(idata["posterior"]["q"], combined=True)
ax.axvline(x=priors["q"].parameters["mu"], color="gray", linestyle="--")
ax.get_figure().suptitle("Imitation Coefficient (q)", fontsize=18, fontweight="bold")
Text(0.5, 0.98, 'Imitation Coefficient (q)')
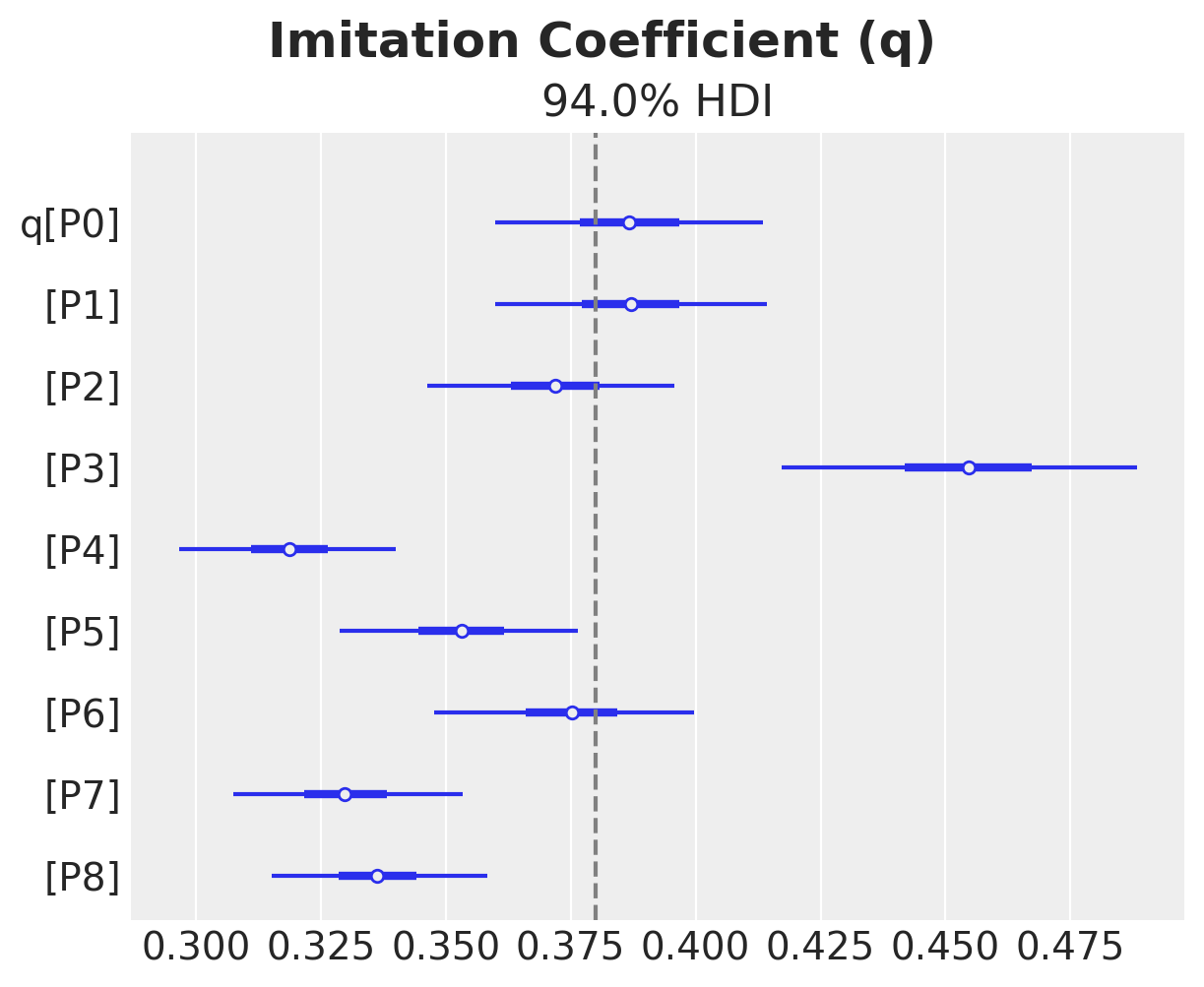
We do see some heterogeneity in the parameters, but overall they are centered around the true values (from the generative model).
Examining Posterior Predictions for Specific Products#
Let’s look at the posterior predictive distributions to see how well our model captures the simulated data.
fig, axes = plt.subplots(
nrows=3, ncols=3, figsize=(15, 12), sharex=True, sharey=True, layout="constrained"
)
idata["posterior_predictive"]["y"].pipe(plot_curve, {"T"}, axes=axes)
for i, ax in enumerate(axes.flatten()):
ax.plot(T, bass_data[:, i], color="black")
fig.suptitle("Posterior Predictive vs Observed Data", fontsize=18, fontweight="bold");
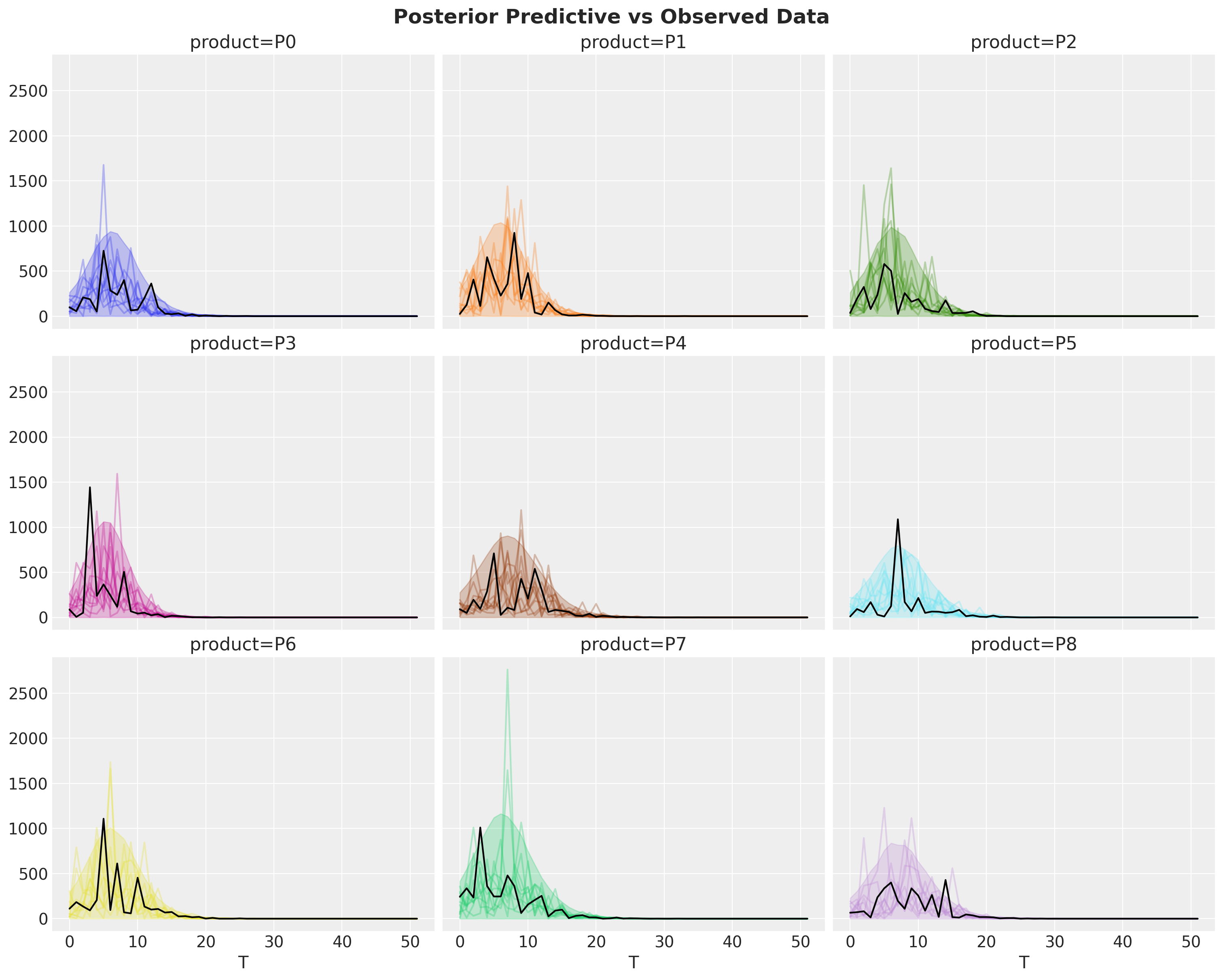
Overall, the model does a good job of capturing the data.
Next, we look into the adopters, which represent the expected value of the likelihood.
fig, axes = plt.subplots(
nrows=3, ncols=3, figsize=(15, 12), sharex=True, sharey=True, layout="constrained"
)
idata["posterior"]["adopters"].pipe(plot_curve, {"T"}, axes=axes)
for i, ax in enumerate(axes.flatten()):
ax.plot(T, bass_data[:, i], color="black")
fig.suptitle("Adopters vs Observed Data", fontsize=18, fontweight="bold");
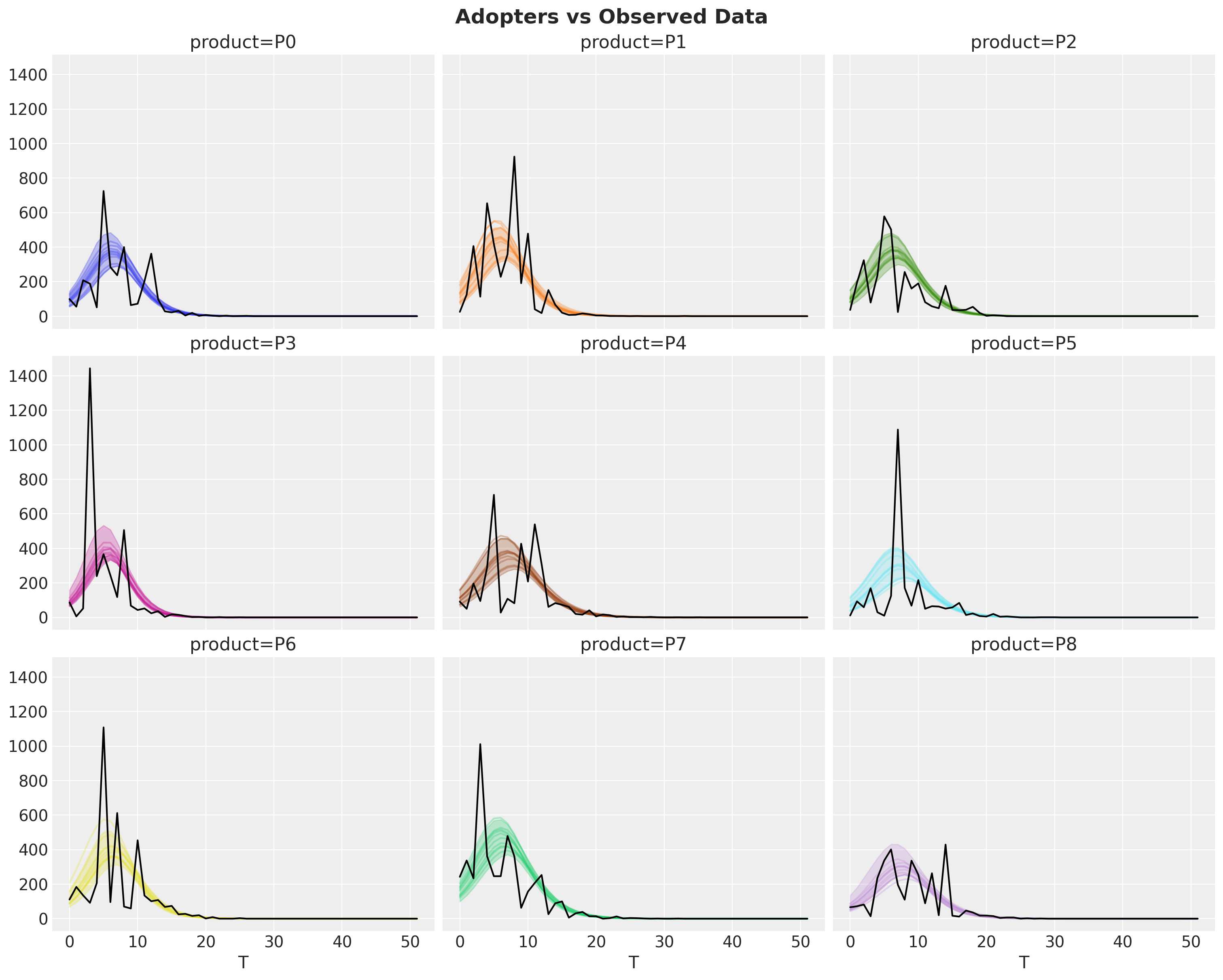
This show the fit is indeed quite reasonable.
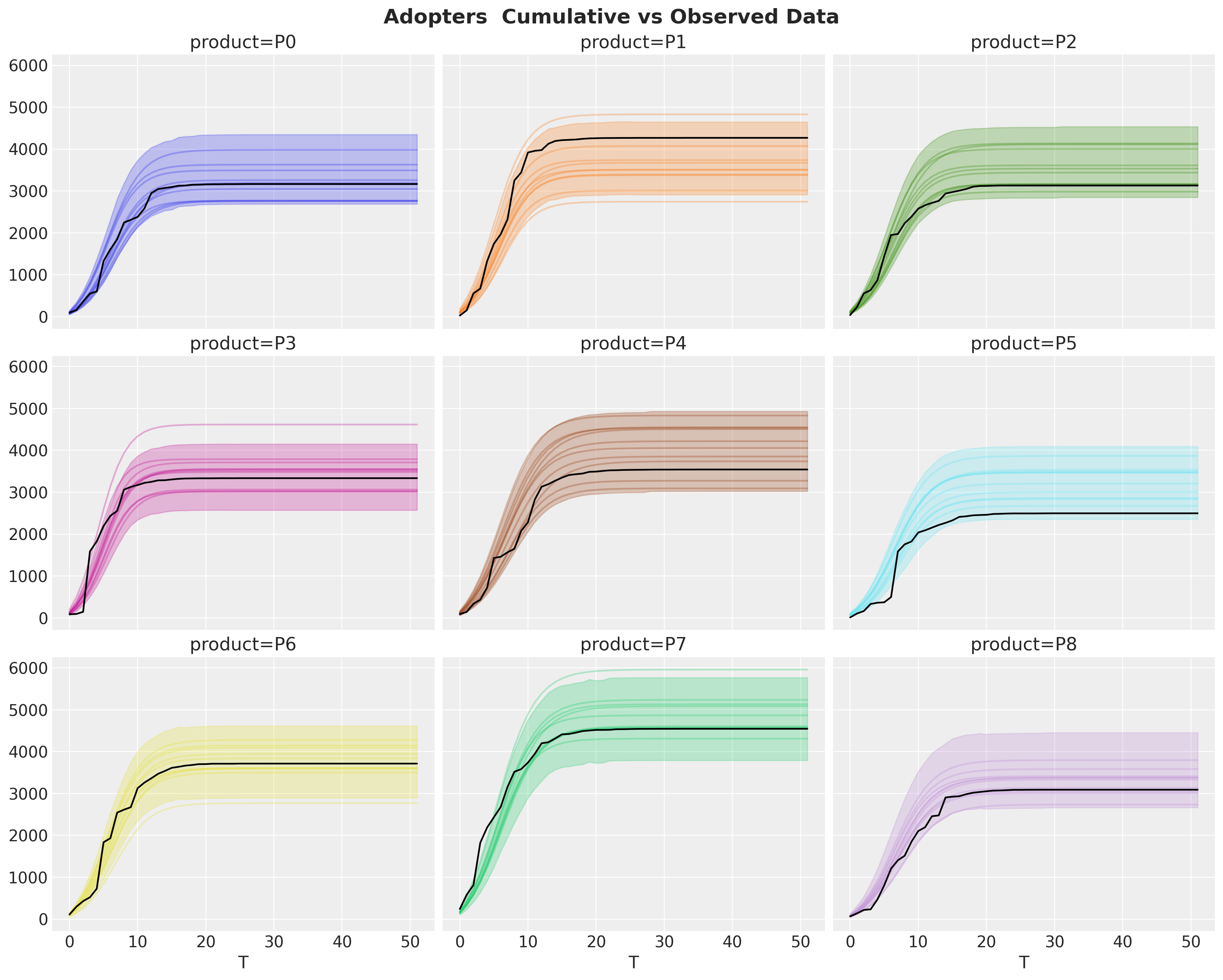
We can also evaluate the model goodness by looking into the cumulative data:
fig, axes = plt.subplots(
nrows=3, ncols=3, figsize=(15, 12), sharex=True, sharey=True, layout="constrained"
)
idata["posterior"]["adopters"].cumsum(dim="T").pipe(plot_curve, {"T"}, axes=axes)
for i, ax in enumerate(axes.flatten()):
ax.plot(T, bass_data[:, i].cumsum(), color="black")
fig.suptitle("Adopters Cumulative vs Observed Data", fontsize=18, fontweight="bold");
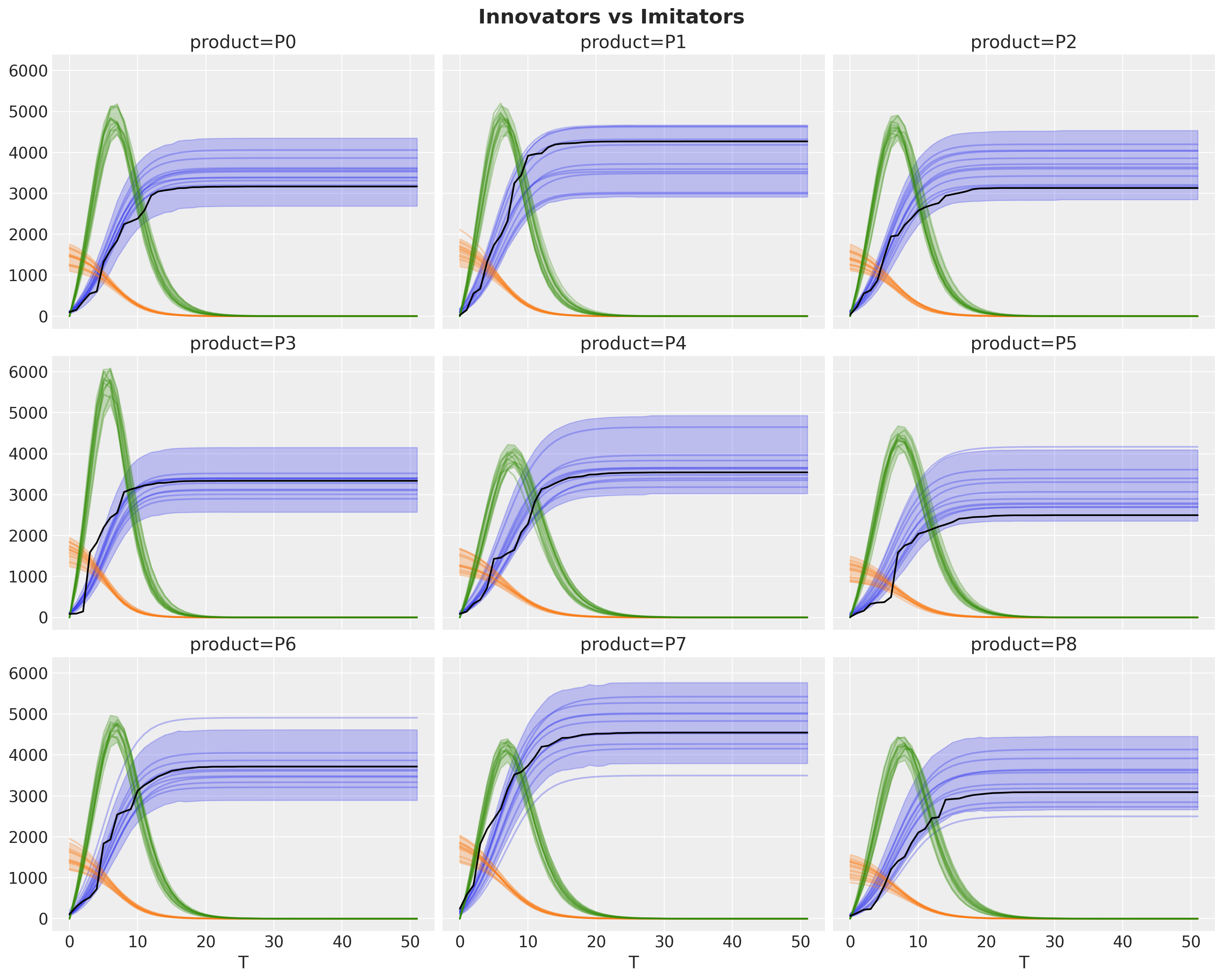
We can enhance this view by looking into the components of the model: innovators and imitators (in orange and green, respectively).
fig, axes = plt.subplots(
nrows=3, ncols=3, figsize=(15, 12), sharex=True, sharey=True, layout="constrained"
)
idata["posterior"]["adopters"].cumsum(dim="T").pipe(
plot_curve, {"T"}, colors=3 * 3 * ["C0"], axes=axes
)
idata["posterior"]["innovators"].pipe(
plot_curve, {"T"}, colors=3 * 3 * ["C1"], axes=axes
)
idata["posterior"]["imitators"].pipe(
plot_curve, {"T"}, colors=3 * 3 * ["C2"], axes=axes
)
for i, ax in enumerate(axes.flatten()):
ax.plot(T, bass_data[:, i].cumsum(), color="black")
fig.suptitle("Innovators vs Imitators", fontsize=18, fontweight="bold");
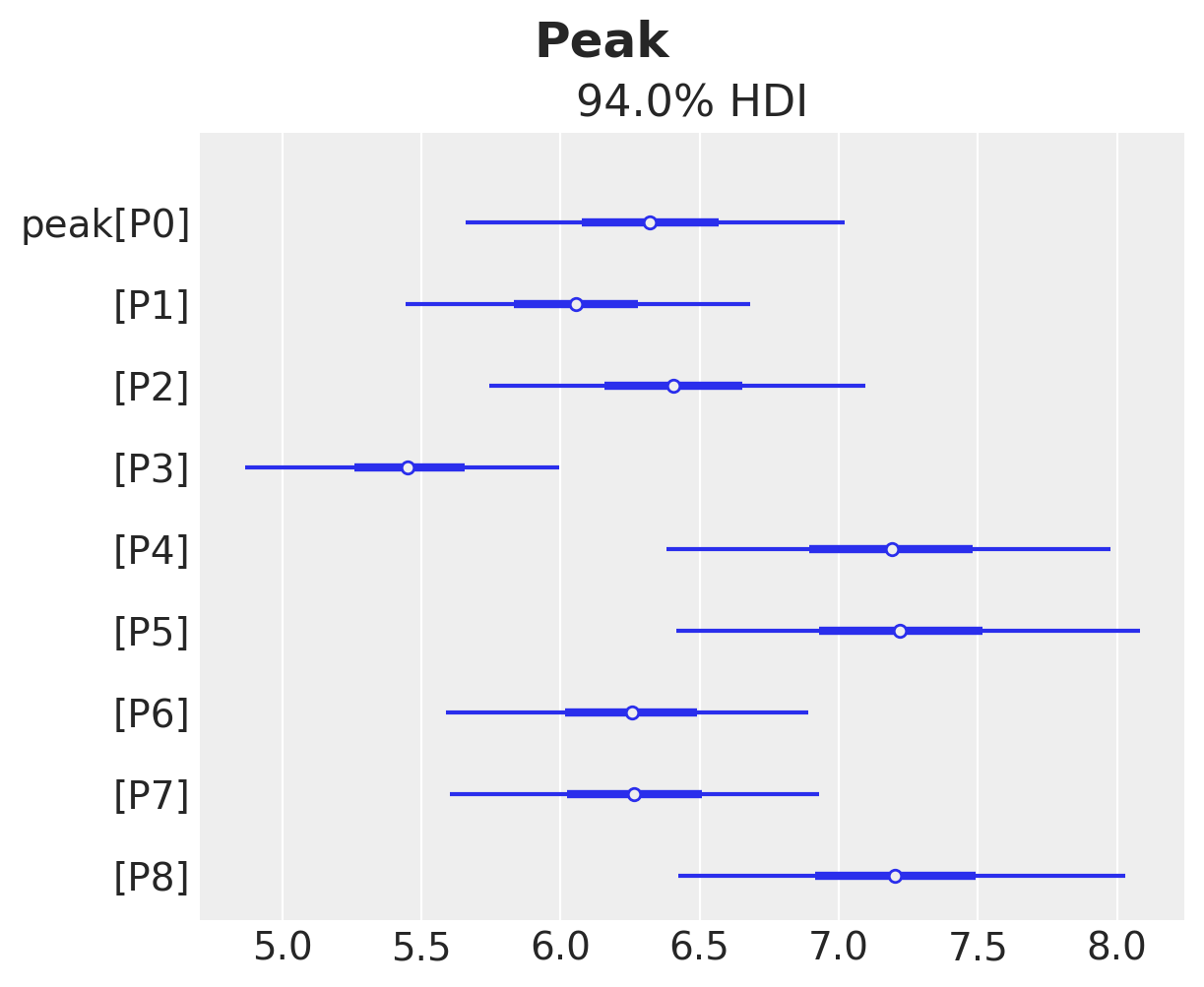
Finally, we can inspect the peak of the adoption curve.
ax, *_ = az.plot_forest(idata["posterior"]["peak"], combined=True)
ax.get_figure().suptitle("Peak", fontsize=18, fontweight="bold");
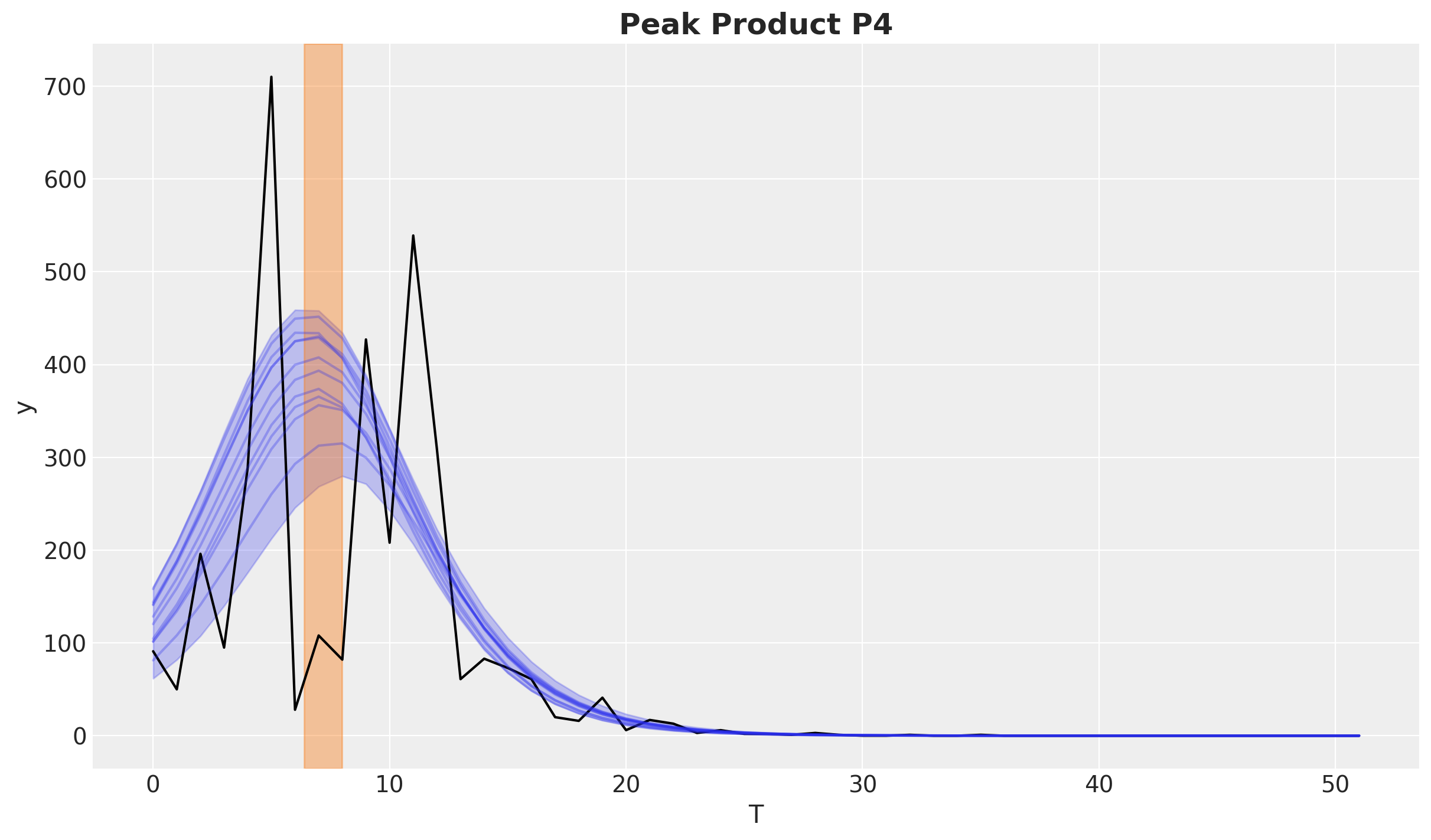
This fits the observed data quite well. Let’s see for example the product P4.
fig, ax = plt.subplots()
product_id = 4
bass_data[:, product_id].plot(ax=ax, color="black")
idata["posterior"]["adopters"].sel(product=f"P{product_id}").pipe(
plot_curve, {"T"}, axes=ax
)
peak_hdi = az.hdi(idata["posterior"]["peak"].sel(product=f"P{product_id}"))["peak"]
ax.axvspan(
peak_hdi.sel(hdi="lower").item(),
peak_hdi.sel(hdi="higher").item(),
color="C1",
alpha=0.4,
)
ax.set_title(f"Peak Product {products[product_id]}", fontsize=18, fontweight="bold");
%load_ext watermark
%watermark -n -u -v -iv -w -p nutpie,pymc_marketing,pytensor
Last updated: Fri Apr 25 2025
Python implementation: CPython
Python version : 3.12.9
IPython version : 9.0.2
nutpie : 0.14.3
pymc_marketing: 0.13.1
pytensor : 2.30.3
pandas : 2.2.3
numpy : 2.1.3
pymc : 5.22.0
matplotlib : 3.10.1
arviz : 0.21.0
pymc_marketing: 0.13.1
xarray : 2025.3.1
Watermark: 2.5.0